What is Data Mesh? A Complete Guide

- Ayesha Binte Habib
Data is at the heart of every modern business decision. Yet, as companies grow, managing data at scale becomes painfully complex. Centralized data lakes and warehouses often create bottlenecks: business teams depend on IT for access, reports are delayed and trust in data quality erodes. This is where modern data management plays an important role. So what is data mesh in modern data management journey? Rather than treating data as something managed by one central team, Data Mesh decentralizes responsibility. It empowers domain experts; the people who know their data best, to own, manage and share it as a product.
But what does that really mean in practice? Let’s break it down.
What is Data Mesh?
Data Mesh is not a specific technology or tool; it’s an organizational and architectural approach to data. It rethinks how data is produced, shared and governed.
Rather than creating a single, massive, centralized system where all the data runs, Data Mesh enables each business domain (such as Sales, Finance, Marketing, Ops) to develop and manage its own data products. These data products are discoverable, reliable, and ready for others to consume.
Think of it as moving from a single, massive highway system (with constant traffic jams) to a network of well-connected local roads, each managed by the people who know the terrain best.
Core Building Blocks of Data Mesh
Data Mesh rests on four foundational principles. They’re called “building blocks” for a reason: remove one and the framework loses its balance.
1. Domain-Oriented Ownership
Traditionally, IT is in control of all corporate information. The catch? IT usually doesn’t have the profound business context. For instance, Finance information is better understood by Finance, not the central data team.
In Data Mesh, every domain has its own data so there are accountability, accuracy and pace. Ownership rests with the individuals nearest to the source.
2. Data as a Product
In many organizations, data is treated as a byproduct of processes. But in a Data Mesh, data is elevated to the level of a product. That means:
- It has a product owner.
- It’s documented, versioned, and tested.
- It’s designed with consumers in mind.
Why? Because usable data doesn’t just appear, it has to be curated and maintained like any other product.
3. Self-Serve Data Platform
Decentralizing ownership does not equate to every domain having to create its own infrastructure. There is a central platform team that offers self-serve facilities, pipelines, storage, catalogs, monitoring, to allow domain teams to publish and consume data without having to become full-time engineers.
This is the foundation of Data Mesh: providing autonomy without sacrificing consistency.
4. Federated Computational Governance
Without government, decentralization can rapidly descend into anarchy. Data Mesh addresses this with federated governance: security, privacy, and interoperability rules are established centrally but automatically enforced by each domain.
How Data Mesh Works?
One of the easiest ways to understand Data Mesh is to think of it like microservices for data. Instead of one massive system that tries to handle everything, each domain team creates and maintains its own “data products.”
These data products are then published into a shared data marketplace or catalog, where they’re documented, discoverable, and easy for others to access. Just like an app store, teams can browse available data products and choose the ones they need.
Consumption is straightforward. Other domains can connect to these products through standardized APIs or query endpoints. The self-serve platform takes care of the technical heavy lifting, managing pipelines, storage, security, and monitoring, so teams can focus on value, not infrastructure.
Governance ties it all together. Instead of leaving compliance and quality to chance, Data Mesh ensures every product adheres to organizational standards. That means consistent naming conventions, proper security controls, and data that’s reliable across the business.
Here’s how this might play out in practice:
- The Sales team publishes a “Customer Orders” data product.
- The Finance team consumes it to reconcile revenue.
- The Marketing team taps into it to analyze customer buying behavior.
- Governance ensures the dataset remains secure, anonymized, and high-quality, no matter who’s using it.
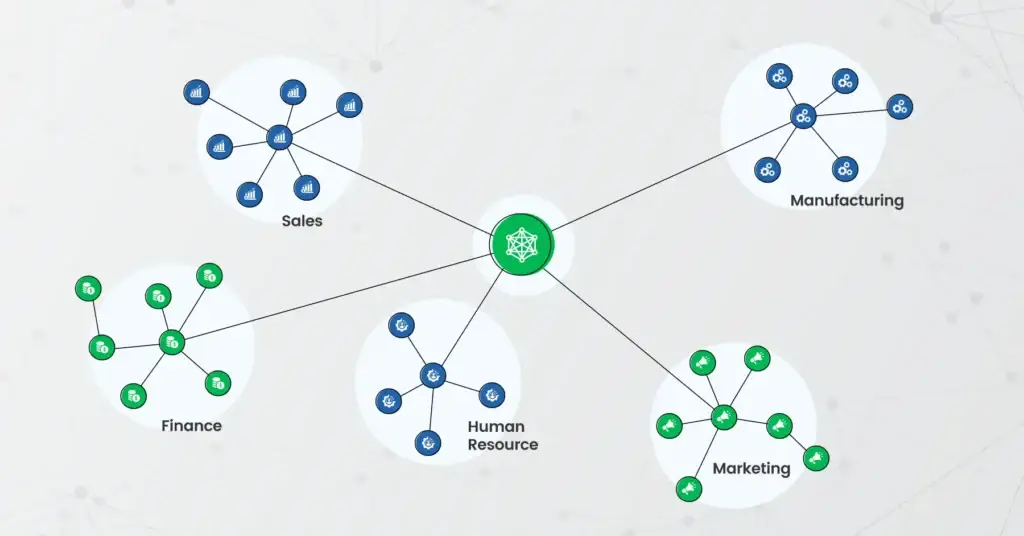
In short, Data Mesh transforms scattered, siloed datasets into a connected ecosystem of trusted, reusable data products and accessible to anyone who needs them.
Implementation Steps:
- Assess Readiness & Culture:
– Is the organization willing to decentralize ownership?
– Do domains understand their data and business processes deeply? - Start Small (Pilot Domains):
– Pick 1–2 high-value domains (e.g., Sales & Finance).
– Build their first data products.
– Prove value before scaling.
- Build the Self-Serve Platform:
– Provide data pipelines, storage, catalogs, monitoring, access management.
– Ensure it’s user-friendly so non-engineering teams can operate. - Define Standards & Governance:
– Decide naming conventions, access policies, SLAs.
– Set up federated governance committees with domain + platform reps. - Scale Gradually:
– Onboard more domains one by one.
– Expand platform capabilities as needed.
– Continuously refine standards. - Monitor & Improve:
– Track KPIs: adoption, data product usage, time-to-insight, quality metrics.
– Use feedback loops to improve data products.
Data Lake vs. Data Mesh
Data Lakes were introduced to solve the rigidity of traditional warehouses. They store vast volumes of raw, semi-structured, and unstructured data in one centralized location. The idea was simple: “store everything now, process later.”
However, as data and teams expanded, Data Lakes often turned into data swamps, vast and unmanageable collections of inconsistent, poorly documented data. Business users still had to depend on data engineers to make sense of it.
Key Differences:
| Aspect | Data Lake | Data Mesh |
|---|---|---|
| Architecture | Centralized repository for all raw and processed data. | Decentralized network of domain-owned data products. |
| Ownership | Managed by a central IT or data platform team. | Each business domain (e.g., Sales, Finance) owns and manages its own data. |
| Data Management | Schema-on-read; flexible but often inconsistent. | Structured through domain-defined standards and governance. |
| Governance | Typically weak or manual, leading to inconsistency. | Federated governance; common rules enforced across domains. |
| Access & Usage | Difficult for non-technical users; requires IT mediation. | Self-serve model; domains publish clean, ready-to-use data. |
| Data Quality | Variable; depends on central team capacity. | High accountability; each domain ensures its data’s reliability. |
| Scalability | Technically scalable but operationally complex. | Scales organizationally as each domain manages its own data. |
Data Warehouse vs. Data Mesh
Data Warehouses have been the backbone of analytics for decades. They offer structured, curated, and historical data designed for reporting and business intelligence. However, their centralized model often slows down decision-making as every new data request flows through the same team.
Key Differences:
| Aspect | Data Warehouse | Data Mesh |
|---|---|---|
| Purpose | Centralized system for structured, historical data used in analytics and reporting. | Distributed architecture that empowers domains to own and share their data products. |
| Ownership | Fully managed by central data or BI teams. | Distributed; business domains take responsibility for their own data. |
| Flexibility | Rigid schema; changes require IT intervention. | Flexible; each domain can evolve its data product independently within shared standards. |
| Speed of Delivery | New reports or datasets depend on central team backlog. | Faster; domains can deliver and iterate on their own data products. |
| Governance | Centralized, often rigid and slow to adapt. | Federated, balance between autonomy and compliance. |
| Data Context | Technical teams manage data they may not fully understand. | Data is managed by those closest to its meaning and usage. |
| Scalability | Scales technically, not organizationally (central team bottlenecks). | Scales both technically and organizationally through domain autonomy. |
Benefits of Data Mesh
Scalability:
Avoids bottlenecks of central data teams; each domain can move at its own pace.Improved Data Quality:
Ownership ensures accountability and higher trust in data.Faster Insights:
Domains deliver ready-to-use, trusted data products directly.Business Alignment:
Data ownership sits with the people who understand it best.Innovation Enablement:
Teams can experiment and create new data products without waiting on IT.Reusability:
Well-designed data products can serve multiple domains, reducing duplication of effort.
Challenges to Watch Out For
- Cultural Shift:
Moving ownership from IT to business teams requires a big mindset change. - Skill Gaps:
Domain teams may need upskilling in data engineering, governance and product thinking. - Tooling Maturity:
Requires strong infrastructure for catalogs, lineage, monitoring and access management. - Consistency:
Hard to ensure standards across domains if governance is weak. - Change Management:
Shifting responsibilities can face resistance from teams used to traditional central control. - Cost and Investment:
Building a self-serve platform and governance framework demands time and resources.
Best Practices
- Start small with one or two domains before scaling.
- Invest in a strong self-serve platform so domains don’t reinvent the wheel.
- Define clear standards for data products (naming, schemas, APIs, SLAs).
- Establish cross-functional data governance committees.
- Measure adoption with metrics like data product usage, data quality, and time-to-insight.
Final Thoughts
Data Mesh is not a technology decision; it’s a change of mindset. It defies the notion that there is one team in the center that can address all data requirements and instead enable domains to take control of their data as products.
For organizations struggling with scale, complexity, and bottlenecks, Data Mesh offers a new way forward: a balance between autonomy and governance, speed and trust, local ownership and global consistency.
Done right, it can transform data from a burden into a true business asset.
Ready for Smarter Data Management? Let’s Talk
Search Blog
Related Resources

What is Data Pipeline?

What is Data Mart?

What is Data Mining?