What is Data Pipeline?

- Ayesha Binte Habib
In today’s data-driven world, businesses generate massive amounts of information every second. Managing this data efficiently is crucial for making informed decisions, improving operations, and gaining a competitive edge. This is where data pipeline comes into play. A data pipeline is a structured process that automates the flow of data from various sources to a destination—be it a data warehouse, analytics tool, or real-time dashboard. By ensuring smooth data movement, transformation, and integration, data pipelines help organizations maintain data accuracy, consistency, and accessibility, forming the backbone of modern data management strategies.
What is Data Pipeline? A Complete Guide
Data Pipeline is a method employed to process unrefined data from diverse origins, refine it, and then deposit it into a data repository like a data lake or data warehouse for scrutiny.
Preceding its storage, data typically undergoes processing such as filtering, masking, and aggregations to guarantee data integration and standardization, especially when the target is a relational database with a specified schema.
Data pipelines are pivotal for data science projects and business intelligence as they prepare data for analysis and reporting. Data can originate from APIs, SQL and NoSQL databases, files, etc., but it often necessitates preprocessing before use.
Data scientists or data engineers commonly manage data preparation, structuring it to meet business needs and managing substantial volumes of data. The type of data processing required in a data pipeline is ascertained through a combination of exploratory data analysis and defined business requirements. Well-designed data pipelines are essential for various data projects, including exploratory data analysis, data visualizations, and machine learning tasks.
Types of Data Pipelines:
- Batch Processing:
Batch processing involves collecting and processing data in large batches at scheduled intervals. Data is collected over a period of time, stored, and then processed in a single batch. Batch processing is well-suited for scenarios where data latency is not critical, such as generating daily reports or performing historical analysis.
- Stream Processing:
Stream processing involves processing data in real-time as it is generated. Data is processed as a continuous stream, allowing for immediate analysis and action on incoming data. Stream processing is ideal for applications that require low latency and real-time insights, such as fraud detection or monitoring IoT devices.
Organizations often use a combination of batch and stream processing to handle different types of data processing requirements. Batch processing is used for tasks that can tolerate some delay, while stream processing is used for tasks that require immediate processing and response.
The Data Pipeline Process:
A data pipeline automates the flow of data from various sources to storage, processing, and visualization platforms. It ensures data is collected, cleaned, stored, processed, and analyzed efficiently. Here’s how it works:
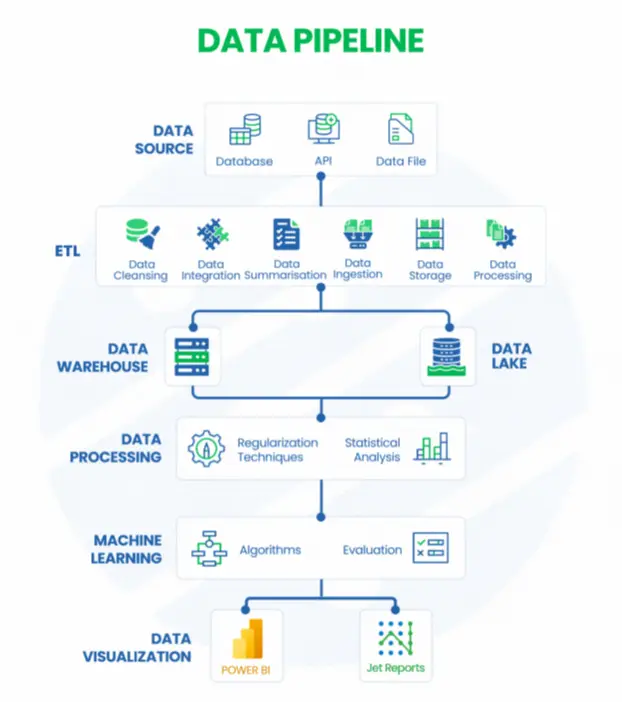
1. Data Source: Gathering Raw Data
Data is collected from multiple sources, including databases (SQL/NoSQL), APIs (real-time data exchange), and data files (CSV, JSON, XML). These sources provide the foundation for business intelligence and analytics.
2. ETL (Extract, Transform, Load): Preparing the Data:
The ETL process ensures data quality and usability. Data cleansing removes errors and duplicates, while integration and summarization combine data from different sources. Data ingestion loads the cleaned data into storage, and processing transforms it for analysis.
3. Data Storage: Organizing and Managing Data
Processed data is stored in either a data warehouse (structured, optimized for fast queries) or a data lake (raw, flexible for future processing). Warehouses support real-time analytics, while lakes store vast amounts of diverse data.
4. Data Processing: Extracting Insights
Regularization techniques ensure data consistency, while statistical analysis identifies trends and patterns. This step refines data for deeper insights and advanced analytics.
5. Machine Learning: Driving AI-Powered Insights
Algorithms detect patterns, classify data, and automate decision-making. The evaluation phase tests models for accuracy, enabling predictive analytics and AI-driven insights.
6. Data Visualization: Presenting Insights for Decision-Making
Power BI and Jet Reports create interactive dashboards and reports, making complex data easy to understand. These tools help businesses monitor key metrics and make data-driven decisions.
Data Pipeline Architecture:
The architecture of a data pipeline typically consists of three core steps: data ingestion, data processing and data storage.
- Data Ingestion:
- Data ingestion is the process of collecting raw data from various sources such as databases, files, APIs, sensors, or streaming platforms.
- This step involves extracting data from the source systems and loading it into the data pipeline for further processing.
- Common tools used for data ingestion include Apache Kafka, AWS Kinesis, and Apache Flume.
- Data Transformation:
- In data transformation, a sequence of tasks is performed to convert data into the necessary format for the target data repository.
- These tasks incorporate automation and governance to streamline repetitive processes like business reporting, ensuring consistent cleansing and transformation of data.
- Data Storage:
- Data storage involves storing processed data in a data repository such as a data lake, data warehouse, or database.
- The refined data is stored in a data repository, ready for access by various stakeholders.
- In the context of streaming data, these refined datasets are commonly referred to as consumers, subscribers, or recipients.
Benefits of Data Pipeline:
Automated data pipeline brings together data from different sources, helping organizations make the most of their data. In simple terms, a data pipeline helps organizations unlock the full potential of their data assets. Here are some benefits of using data pipelines:
- Improved Efficiency:
Data pipeline automate data workflows, which means less manual work and better efficiency in handling data. This makes data operations smoother, helps organizations use their resources more wisely, and reduces costs associated with manual data management. - Scalability:
Data pipeline can handle large amounts of data, allowing organizations to expand their operations as their data needs grow. With a scalable setup, businesses can manage increasing data demands without any drop in performance. - Better Data Quality:
Data pipeline clean and transform data, enhancing its quality and ensuring it’s accurate for analysis and decision-making. This ensures that organizations can rely on the insights they get from their data to guide their business activities. - Real-time Insights:
The Data pipeline provide access to real-time data, which means organizations can get up-to-date information for immediate action. By using timely data insights, businesses can make quick and informed decisions, giving them an edge in fast-paced markets.
- Cost-effectiveness:
The Data pipeline optimize resource use, reducing costs related to manual data processing. By saving time and effort in handling data, organizations can allocate their resources efficiently and achieve cost-effectiveness.
Data Pipeline Use cases:
As big data continues to grow, data management becomes an ever-increasing priority. Data pipelines serve various functions, especially in business applications:
- Exploratory Data Analysis (EDA):
Data scientists use EDA to analyze and investigate datasets, summarizing their main characteristics. EDA helps determine the best way to manipulate data sources to get needed answers, making it easier to discover patterns, spot anomalies, test hypotheses, or check assumptions.
- Data Visualizations:
Visual representations of data, such as charts, plots, infographics, and animations, help communicate complex data relationships and insights in an easy-to-understand manner.
- Machine Learning:
A branch of artificial intelligence, uses data and algorithms to imitate the way humans learn, gradually improving accuracy. Statistical methods and algorithms are trained to make classifications or predictions, uncovering key insights in data mining projects.
- Data Observability:
This practice uses various tools to monitor, track, and alert for both expected events and anomalies, ensuring the accuracy and safety of the data being used.
- Data Integration and Data Warehousing:
Data pipelines are crucial for integrating data from multiple sources and storing it in a data warehouse for analysis. This allows organizations to have a unified view of their data, enabling better decision-making.
- Real-time Analytics:
Data pipelines can process streaming data in real-time, enabling organizations to analyze data as it is generated and make timely decisions.
- Data Migration:
Data pipeline can be used to migrate data between systems, such as moving data from an on-premises database to a cloud-based data warehouse.
- Log Processing and Analysis:
Data pipeline can process and analyze log data from applications and systems, helping organizations monitor performance, detect issues, and improve security.
Challenges and Limitations of Data Pipeline:
While data pipeline offer numerous advantages, they also come with challenges and limitations that organizations must address:
Complexity in Implementation:
Designing and maintaining a robust data pipeline requires expertise in data engineering, integration, and automation. Poorly designed pipelines can lead to inefficiencies and failures.Data Quality Issues:
Inconsistent or incomplete data from various sources can lead to inaccurate insights. Ensuring data validation, cleansing, and transformation at every stage is crucial but can be resource-intensive.Scalability Constraints:
As data volume grows, pipelines must be able to scale efficiently. Without proper infrastructure, organizations may face bottlenecks, slow processing speeds, or system failures.Latency and Real-Time Processing Challenges:
While real-time data pipelines enable faster decision-making, maintaining low latency in streaming data environments requires powerful computing resources and optimized architecture.Security and Compliance Risks:
Data pipelines handle sensitive information, making them vulnerable to breaches and compliance violations. Implementing encryption, access controls, and governance policies is essential but adds complexity.High Maintenance and Monitoring Overhead:
Pipelines require continuous monitoring, debugging, and optimization to prevent failures, data loss, or corruption. Unexpected schema changes or source disruptions can break pipelines, demanding quick fixes.Cost Considerations:
Cloud-based and on-premise data pipelines incur costs related to storage, compute resources, and third-party tools. Inefficient pipelines can lead to excessive spending on data processing and storage.
In Conclusion
In conclusion, data pipelines are crucial components of modern data management, facilitating the collection, processing, and analysis of data to drive informed decision-making. They play a pivotal role in various applications such as exploratory data analysis, data visualizations, machine learning, and real-time analytics. By enabling organizations to integrate data from multiple sources, data pipelines help break down data silos and improve overall data quality. As data continues to grow in volume and complexity, data pipelines will remain essential tools for organizations looking to harness the power of data to gain insights and drive business success.
Talk to our BI Experts!
Search Blog
Related Resources

What is Data Mesh? A Complete Guide

What is Data Mart?
What are Data Lakes?